目次
0. Introduction
DynamoDB をバックアップ及びリストアしたい目的で、そのエクスポート方法やインポート方法として、Data Pipeline を用いた方法があります。 基本的には、このページの内容になります。
-
対象となる読者
- DynamoDB をバックアップ及びリストアしたいと思っている方
-
本記事の価値
- DynamoDB のエクスポート方法やインポート方法を知ることで、そのバックアップ及びリストアを実行することができます。
-
前提
- システムで DynamoDB を運用している方
1. AWS Data Pipeline
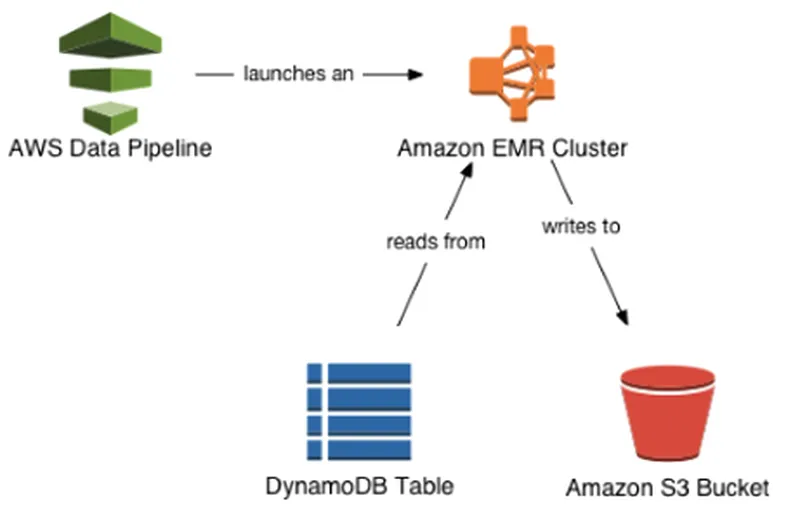
AWS Data Pipelineは、データの移動と変換を自動化するために使用できるウェブサービスです。データ駆動型のワークフローを定義することが出来るので、DynamoDB のデータを S3 に移動したり、S3 のデータを DynamoDB に移動したりすることが可能となっています。これらの基本的なユースケースはテンプレートとして、「Export DynamoDB table to S3」が「Import DynamoDB backup data from S3」が用意されています。
2. Data Pipeline 用の IAM ロールを準備
まず始めに、以下の 2 種類の IAM ロールを作る必要があります。
- 「DataPipelineDefaultRole」: パイプラインによって自動的に実行されるアクション。
- 「DataPipelineDefaultResourceRole」: パイプラインによって自動的にプロビジョンされる AWS リソース。DynamoDB データのエクスポートとインポートの場合、これらのリソースには Amazon EMR クラスターと、そのクラスターに関連付けられている Amazon EC2 インスタンスが含まれます。
追加する手順は、こちらを参照してください。

ハマりポイントとしては、「DataPipelineDefaultResourceRole」のロール作成です。 DataPipelineDefaultResourceRole not appearing in EC2 Instance Role dropdownにあるように、インスタンスプロファイルにリンクされた新しい IAM ロールを作成する必要があります。「Create role」(ロールの作成)時に、お客様のユースケースとして [EC2] を選択してから、[次のステップ: 権限] を選択するところがポイントです。そのロールに以下の新しいポリシーをアタッチしてください。
3. DynamoDB から Amazon S3 にデータをエクスポートする
それでは、DynamoDB のエクスポート用のパイプラインを作っていきます。
- “Name"には、適当に「ExportTest」
- “Source"には、「Export DynamoDB table to S3」を選択
- “Source DynamoDB table name"には、エクスポートしたい DynamoDB のテーブル名を記入する。
- “Output S3 folder"には、エクスポート先の S3 バケットを指定する(あらかじめ用意しておく)。
- “Region of the DynamoDB table"には、エクスポートしたい DynamoDB のテーブルがあるリージョンを記入する。“ap-northeast-1”

- “Schedule"には、ボタンを押した時に起動してほしいので、Run で「on pipline activateion」を選択。
- “Logging"には、「Enabled」を選択し、ログ出力用の S3 バケットを指定する(あらかじめ用意しておく)。ログ出力無しでも特に問題はない。

-
“Security/Access"の"IAM roles"には、前述で作成したものを指定します。
- Pipeline role:「DataPipelineDefaultRole」
- EC2 instance role:「DataPipelineDefaultResourceRole」
-
最後に、すべての設定が正しいことを確認したら、[Activate] (有効化) をクリックします。
これで、パイプラインが作成されます。このプロセスが完了するまでに数分かかることがあります。 AWS Data Pipeline コンソールで進捗状況をモニターすることができます。 エクスポートが完了したら、Amazon S3 コンソールに移動して、エクスポートファイルを表示できます。 出力ファイル名は、ae10f955-fb2f-4790-9b11-fbfea01a871e_000000 のように識別子の値で、拡張子はありません。
4. Amazon S3 から DynamoDB にデータをインポートする
エクスポートファイルから Amazon S3 にデータをインポートできます。ただし、次のすべての条件を満たしていることが前提です。
- インポート先テーブルがすでに存在する (インポートプロセスによってテーブルは作成されません。)
- インポート先テーブルとソーステーブルのキースキーマが同じ
インポート先テーブルは空である必要はありません。ただしインポートプロセスでは、インポート先テーブルのデータ項目のうち、エクスポートファイルの項目とキーが同じものはすべて置き換えられます。たとえば、Customer テーブルに CustomerId というキーがあり、そのテーブルに 3 つの項目 (CustomerId 1、2、3) のみがあるとします。エクスポートファイルにも CustomerID 1、2、3 のデータ項目がある場合、インポート先テーブルの項目はエクスポートファイルのものと置き換えられます。エクスポートファイルに CustomerId 4 のデータ項目もある場合、その項目がインポート先テーブルに追加されます。
方法は、エクスポート時とほぼ同様なので、内容は省略します。
- “Source"には、「Import DynamoDB backup data from S3」を選択
